What does MPEG-1 audio standardise?
MPEG-1 audio standardizes three different coding schemes for digitized sound waves called Layers I, II, and III. It does not standardize the encoder, but rather standardizes the type of information that an encoder has to produce and write to an MPEG-1 conformant bitstream as well as the way in which the decoder has to parse, decompress, and resynthesize this information in order to regain the encoded sound. The encoded sound bitstream can be stored together with an encoded video bitstream and other data streams in a so-called MPEG-1 systems stream.
What are the typical applications of MPEG-1 Audio?
Within the professional and consumer market, four fields of applications can be identified: broadcasting, storage, multimedia, and telecommunication. This variety of applications is possible because of the wide range of bitrates and the numerous configurations allowed within the MPEG-1 Audio standard. Some of the most important applications are:
What is so special about MPEG-1 audio coding?
MPEG-1 audio aims for generic sound waves, i.e. it is not restricted to e.g. speech
signals, but codes all types of sound signals.
It performs perceptual audio coding rather than lossless coding. In lossless coding,
redundancy in the waveform is reduced to compress the sound signal, and the decoded
sound wave does not differ from the original sound wave. On the contrary, a
perceptual audio codec does not attempt to retain the input signal exactly after encoding
and decoding, rather its goal is to ensure that the output signal sounds the same to a
human listener. It aims at eliminating those parts of the sound signal that are irrelevant
to the human ear, i.e. that are not heard. Roughly speaking, an MPEG-1 audio encoder
transforms the sound signal into the frequency domain, eliminates those frequency
components that are masked by stronger frequency components (i.e. cannot be heard), and
packages this analyzed signal into an MPEG-1 conformant audio bitstream.
What are the different layers in MPEG-1?
The different layers have been defined because they all have their
merits. Basically, the complexity of the encoder and decoder, the
encoder/decoder delay, and the coding efficiency increase when going
from Layer I via Layer II to Layer III.
Layer I has the lowest
complexity and is specifically suitable for applications where also the
encoder complexity plays an important role.
Layer II requires a
more complex encoder and a slightly more complex decoder, and is
directed towards 'one to many' applications, i.e. one encoder serves
many decoders. Compared to Layer I, Layer II is able to remove more of
the signal redundancy and to apply the psychoacoustic threshold more
efficiently.
Layer III is again more complex and is directed
towards lower bit rate applications due to the additional redundancy and
irrelevancy extraction from enhanced frequency resolution and
Huffman coding.
The term 'layers' suggests that the higher layers are 'on top' of the lower layers. Is that true?
Not exactly. But it is true that the main functional modules of the lower layers are
also used by the higher layers. E.g. the subband filterbank of Layer I is also used by Layer
II and Layer III, Layer II adds a more efficient coding of side information, Layer III
adds a frequency transform in all the subbands.
The three layers have been defined to be compatible in a hierarchical way, i.e. a 'full
Layer N' decoder is able to decode bitstreams encoded in Layer N and all layers below N.
Consequently, a 'full Layer III' decoder accepts Layer I, II, and III bitstreams and a
'full Layer II' decoder accepts Layer I and II bitstreams, however a Layer I decoder only
accepts Layer I bitstreams.
Nevertheless, MPEG-1 Audio decoders may exist which do not support the full
functionality for a certain layer, or do not support the lower layers. These decoders may
however not be referred to as (full) Layer N decoder.
Originally, the file extension ".mp3" was created with the emergence of MPEG-1 Layer III encoder and decoder software for Windows. After standardisation of MPEG-2, sound files encoded with the MPEG-2 lower sampling rate extension of Layer III are also called "MP3"-files. Sometimes MP3 is wrongly called MPEG-3.
The primary psychoacoustic effect that the perceptual MPEG-1 audio coder uses is called
'auditory masking', where parts of a signal are not audible due to the function of the
human auditory system. For example, if there is a sound that consists mainly of one
frequency, all other sounds that consist of a closeby frequency but are much quieter will
not be heard. The parts of the signal that are masked are commonly called 'irrelevant', as
opposed to parts of the signal that are removed by a lossless coding operation,
which are termed 'redundant'.
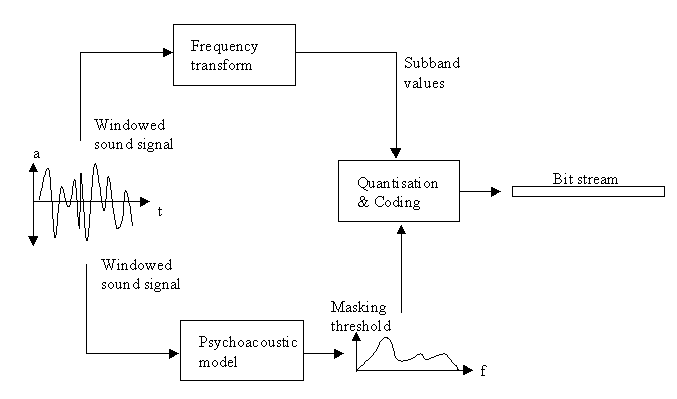
In order to remove this irrelevancy, the encoder contains a psychoacoustic model (see
Figure 1). This psychoacoustic model analyzes the input signals within consecutive time
blocks and determines for each block the spectral components of the input audio signal by
applying a frequency transform. Then it models the masking properties of the human
auditory system, and estimates the just noticeable noise-level for each frequency band,
sometimes called the threshold of masking.
In parallel, the input signal is fed through a time-to-frequency mapping, resulting in
spectrum components for subsequent coding. In its quantisation and coding stage, the
encoder tries to allocate the available number of data bits in a way that meets both the
bitrate and masking requirements taking into account the calculated thresholds of masking.
The information on how the bits are distributed over the spectrum is contained in the
bitstream as side information.
The decoder is much less complex, because it does not require a psychoacoustic model and
bit allocation procedure. Its only task is to reconstruct an audio signal from the coded
spectral components and associated side information.
Figure 1: Overview of MPEG-1 audio encoding
What is the general layout of the bit stream?
The digitized sound signal is devided up into blocks of 384 samples in Layer I and 1152 samples in Layers II and III. Such a block is encoded within one MPEG-1 audio frame. An MPEG-1 audio stream therefore consists of consecutive audio frames. A frame consists of a header and the encoded sound data. A Layer III frame may distribute its encoded sound data over several consecutive other frames if those frames do not require all of their bits. The header of a frame contains general information such as the MPEG Layer, the sampling frequency, the number of channels, whether the frame is CRC protected, whether the sound is an original etc. Although most of this information may be the same for all frames, MPEG decided to give each audio frame such a header in order to simplify synchronization and bitstream editing.
What bit rates are supported by MPEG-1 Audio?
In order to be applicable to a large number of different applications scenarios, MPEG-1 supports a wide range of bit rates from 32 kbit/s to 320 kbit/s. The "Low Sampling Frequency" (LSF) extension of MPEG-2 extends this range down to 8 kbit/s. In addition, switching of bit rates at the frame level is explicitly included in the standard thus allowing applications to adapt their bit rate to environmental conditions.
Is Variable Bit Rate allowed in MPEG-1 Audio?
For Layer III, the answer is simply 'yes'. The average bit rate is the one given in the
header of a Layer III frame, but as the bits may be distributed over several frames, this
effectively implies a variable bit rate.
For Layers I and II, according to the standard, it is not mandatory for decoders to
support Variable Bit Rate (VBR). However, in practice the majority of the decoders do
support Variable Bit Rate, and it is perfectly in line with the standard to specify for a
certain application that decoders should support VBR. This is implemented by specifying
for each audio frame separately the bit rate at which it is encoded.
What stereo modes are supported by MPEG-1 Audio?
MPEG-1 audio works for one- and two-channel audio signals. A method called joint stereo coding can be used to exploit some redundancy between left and right channels of a stereo audio signal. Four different modes are standardized:
What is the Signal-To-Noise Ratio (SNR) of MPEG-1 Audio?
For a perceptual codec, this is not really a relevant question. The SNR is a very bad
measure of perceptual audio quality, even for a waveform coder. The SNR measured in a
conventional way, may vary from a few dB up to more than 100 dB, mostly depending on the
signal, while no noise is audible in any of these cases. Within the International
Telecommunication Union (ITU-R), a task group (TG 10/4) is working on the development of a
more appropriate objective measurement system, based on perceptual models. For the moment,
one has to rely on the human ear as a measuring instrument, i.e. there are no other
reliable means to determine the quality of a perceptual codec than listening tests. Even
when a standardised perceptually based objective measurement system is available,
listening tests will still be wise for comparison of different audio codecs.
On the basis of psychoacoustics, it must be noted that within the range of 5 to 80 dB SNR,
it is easily possible to generate two test signals, one that can be exactly reproduced in
the perceptual sense, and one that cannot, showing the large range over which SNR is not
meaningful as a quality measure.
How is the performance of MPEG-1 Audio with respect to cascading, i.e. multiple coding?
This functionality was tested by the International Telecommunication Union (ITU-R).
They tested various configurations of repeated encoder/decoder chains at different
bitrates with a variety of audio coding algorithms.
MPEG-1 Audio performed best in this test. On the basis of these tests, ITU-R recommends
the use of MPEG-1 Audio Layer II for contribution (i.e. link between broadcasting studios
with provisions for post processing), for distribution (i.e. link between the broadcasting
and transmitter station) and for emission (i.e. final transmission between transmitter and
receiver at home). The use of MPEG-1 Audio Layer III is recommended for commentary links,
i.e. a link for speech signals which are transmitted to the broadcasting station using
e.g. one B-channel of an ISDN line.
What kind of support does MPEG provide for implementers of MPEG Audio?
MPEG provides different kinds of support to implementers. Firstly,
a Technical Report is issued that contains software that describes the
decoder and an example encoder. This software can be used by
implementers to analyze and to get accustomed with the algorithms, and
could be used as a basis for an implementation. The encoder can be
used to generate test sequences. The Technical Report is published as
part 5 of the standard, i.e. ISO/IEC 11172-5 for MPEG-1 and ISO/IEC
13818-5 for MPEG-2, ISO/IEC 13818-5 for MPEG-2 AAC.
Secondly, a conformance document is issued. This document provides
guidelines to test conformance to the standard of bitstreams, and
conformance of decoders. It also describes the accuracy level that a
decoder should meet in order to be called an MPEG audio decoder or a
'high accuracy' MPEG Audio decoder.
An important part of the conformance document is a set of
bitstreams and the corresponding reference decoder output, that
address several functionalities of the decoder. The conformance
document is published as part 4 of the standard, i.e. ISO/IEC 11172-4
for MPEG-1 and ISO/IEC 13818-4 for MPEG-2 and MPEG-2 AAC.
For MPEG-2 ISO/IEC 13818-5 a CD ROM was released which contains
all the reference bitstreams needed to perform the conformance test of
the decoder implementations. The CD ROM can be ordered directly from
the ISO/IEC Copyright Office.
How many MPEG-1 Audio decoders are already in the market-place?
Because of the widespread applications, it is rather difficult to give exact numbers. But at the end of 1996 a rough estimation of decoders in the marketplace gives a total number of several millions.
What are the reasons that MPEG-1 Audio is used so widely?
Thanks to its technical merits and excellent audio quality performance, several standardisation bodies include the MPEG-1 Audio standard in their recommendation. ITU-R (International Telecommunication Union) issued in 1994 the recommendation BS.1115, to use MPEG Audio for audio as well as television broadcasting, including contribution, distribution, commentary and emission links. In 1995, DAVIC (Digital Audio Visual Council) specified the use of MPEG Audio for mono and stereo audio signals. ETSI (European Telecommunication Standardisation Institute) included in January 1995 MPEG-1 and MPEG-2 Audio in their Standard on DAB Standard pr ETS 300 401, 'Radio Broadcasting system; Digital Audio Broadcasting (DAB) to mobile, portable and fixed receivers' and later in the ETR 154 on 'Digital broadcasting systems for television; Implementation guidelines for the use of MPEG-2 systems; Video and audio in satellite and cable broadcasting applications'. ITU-T recommended in 1995 in its recommendation J.52 'Digital Transmission of High-Quality Sound-Programme Signals using one, two or three 64 kbit/s Channels per Mono Signal (and up to Six per Stereo Signal)' the use of MPEG-1 and MPEG-2 Audio as an audio coding system to provide high quality audio over telecommunication lines.
What is the relation between MUSICAM and MPEG-1 Audio Layer II?
MUSICAM was the name of an audio coding system submitted to MPEG, which became the basis for MPEG-1 Audio Layer I and II. Since the finalisation of MPEG-1 Audio, the original MUSICAM algorithm is not used anymore. The name MUSICAM is however mistakenly still used regularly when MPEG-1 Audio Layer II is meant. This is especially to be avoided because the name MUSICAM is trademarked by different companies in different regions of the world.
Can you propose more detailed information in the literature?
Since 1992, many articles about MPEG-1 Audio coding have been published all over the world. The following list of standards, recommendations, and articles provides you with more information, and gives you both, a better overview and more detailed knowledge, so that you will become a 'real MPEG Audio fan'.
What's the status of the standardisation process?
MPEG-1 was finalised in 1992 and resulted in the International Standard ISO/IEC 11172-3 which was published in 1993.
Where can I find information on MPEG-1 licensing ?
Information on licensing of MPEG-1 Layer I and Layer II can be found at:
http://www.audiompeg.com/ (SISVEL, Italy)
http://www.licensing.philips.com/information/mpeg/
Information on licensing of MPEG-1 Layer III can be found at:
http://www.mp3licensing.com/
http://www.iis.fhg.de/amm/legal/index.html
The information above is provided for convenience of the reader. MPEG, however, is not in a position to guarantee the validity of any claim made by a party with respect to IPR ownership.
![]()

