MPEG Audio FAQ
I'm looking for an introduction to MPEG-4 Audio?
Here is an introduction to MPEG-4 Audio:
Coding of Audio Objects
MPEG-4 Audio provides tools for coding of both natural and synthetic
audio objects. It permits to represent natural sounds
(such as speech and music) and to synthesize sounds based on structured descriptions.
The representation for synthesized sound can be derived from text data or so-called
instrument descriptions and by coding parameters to provide effects, such as reverberation
and spatialization. The representations provide compression and other functionalities,
such as scalability or play-back at different speeds.
Test Results:
The MPEG-4 Audio coding tools covering 6kbit/s to 24kbit/s have undergone verification
testing for an AM digital audio broadcasting application in collaboration with the
NADIB(Narrow Band Digital Broadcasting) consortium. With the intent of identifying a
suitable digital audio broadcast format to provide improvements over the existing AM
modulation services, several codec configurations involving the MPEG-4 CELP, TwinVQ, and
AAC tools have been compared to a reference AM system. It was found that higher quality
can be achieved in the same bandwidth with digital techniques and that scalable coder
configurations offered performance superior to a simulcast alternative.
Natural Sound
MPEG-4 standardizes natural audio coding at bitrates ranging from 2 kbit/s up to and
above 64 kbit/s. The presence of the MPEG-2 AAC standard within the MPEG-4 tool set will
provide for general compression of audio in the upper bit rate range. For these, the
MPEG-4 standard defines the bitstream syntax and decoding processes in terms of a set of
tools. In order to achieve the highest audio quality within the full range of bitrates and
at the same time provide the extra functionalities, three types of coding structures have
been incorporated into the standard:
Parametric coding techniques cover the lowest bitrate range i.e. 2 - 4 kbit/s for
speech with 8 kHz sampling frequency and 4 - 16 kbit/s and for audio with 8 or 16 kHz
sampling frequency.
Speech coding at medium bitrates between about 6 - 24 kbit/s uses Code Excited Linear
Predictive (CELP) coding techniques. In this region, two sampling rates, 8 and 16 kHz, are
used to support both narrowband and wideband speech, respectively.
For bitrates starting below 16 kbit/s, time-to-frequency (T/F) coding techniques,
namely the TwinVQ and AAC codecs, are applied. The audio signals in this region typically
have sampling frequencies starting at 8 kHz.
To allow optimum coverage of the bitrates and to allow for bitrate and bandwidth
scalability, a general framework has been defined. This is illustrated in Figure 3.
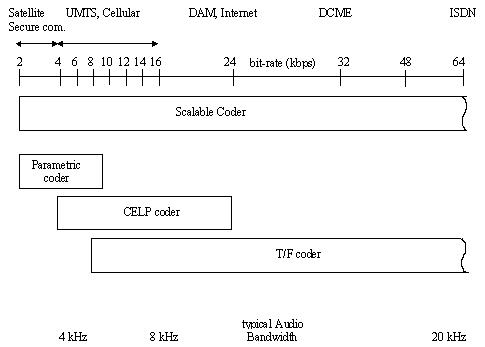
Figure 3: General Framework of MPEG-4 Audio.
Starting with a coder operating at a low bitrate, by adding enhancements, such as the
addition of BSAC (Bit sliced arithmetic coding) to an AAC coder for fine grain
scalability, both the coding quality as well as the audio bandwidth can be improved. These
enhancements are realized within a single coder or, alternatively, by combining different
coding techniques.
Scalability:
Bit rate scalability allows a bitstream to be parsed into a bitstream of lower bit rate
that can still be decoded into a meaningful signal. The bit stream parsing can occur
either during transmission or in the decoder. Bandwidth scalability is a particular case
of bit rate scalability whereby part of a bitstream representing a part of the frequency
spectrum can be discarded during transmission or decoding. Encoder complexity scalability
allows encoders of different complexity to generate valid and meaningful bitstreams.
The decoder complexity scalability allows a given bitstream to be decoded by decoders
of different levels of complexity. The audio quality, in general, is related to the
complexity of the encoder and decoder used. Error robustness provides the ability for a
decoder to avoid or conceal audible distortion caused by transmission errors.
Scalability works within some MPEG-4 tools, but can also be applied to a combination of
techniques, e.g. with Twin VQ as a base layer and AAC for the enhancement layer(s).
The MPEG-4 systems layer facilitates the use of different tools and signaling this, and
thus codecs according to existing standards can be accommodated. Each of the MPEG-4 coders
is designed to operate in a stand-alone mode with its own bitstream syntax. Additional
functionalities are realized both within individual coders, and by means of additional
tools around the coders. An example of a functionality within an individual coder is pitch
change within the parametric coder.
Synthesized Sound
Decoders are also available for generating sound based on structured inputs. Text input
is converted to speech in the Text-To-Speech (TTS) decoder, while more general sounds
including music may be normatively synthesized. Synthetic music may be delivered at
extremely low bitrates while still describing an exact sound signal.
Text To Speech:
TTS coders bit rate range from 200 bit/s to 1.2 Kbit/s which allows a text or a text
with prosodic parameters (pitch contour, phoneme duration, and so on) as its inputs to
generate intelligible synthetic speech. It includes the following functionalities:
- Speech synthesis using the prosody of the original speech
- Lip synchronization control with phoneme information.
- Trick mode functionality: pause, resume, jump forward/backward.
- International language and dialect support for text. (i.e., it can be signaled in the
bitstream which language and dialect should be used)
- International symbol support for phonemes, and support for specifying age, gender,
speech rate of the speaker.
Note that MPEG-4 provides a standardized interface for the operation of a Text To
Speech coder (TTSI = Text To Speech Interface) rather than a normative TTS synthesizer
itself.
Score Driven Synthesis:
The Structured Audio tools decode input data and produce output sounds. This decoding
is driven by a special synthesis language called SAOL (Structured Audio Orchestra
Language) standardized as a part of MPEG-4. This language is used to define an
"orchestra" made up of "instruments" (downloaded in the bitstream, not
fixed in the terminal) which create and process control data. An instrument is a small
network of signal processing primitives that might emulate some specific sounds such as
those of a natural acoustic instrument. The signal-processing network may be implemented
in hardware or software and include both generation and processing of sounds and
manipulation of prestored sounds.
MPEG-4 does not standardize "a method" of synthesis, but rather a method of
describing synthesis. Any current or future sound-synthesis method can be described in
SAOL, including wavetable, FM, additive, physical-modeling, and granular synthesis, as
well as non-parametric hybrids of these methods.
Control of the synthesis is accomplished by downloading "scores" or
"scripts" in the bitstream. A score is a time-sequenced set of commands that
invokes various instruments at specific times to contribute their output to an overall
music performance or generation of sound effects. The score description, downloaded in a
language called SASL (Structured Audio Score Language), can be used to create new sounds,
and also include additional control information for modifying existing sound. This allows
the composer finer control over the final synthesized sound. For synthesis processes which
do not require such fine control, the established MIDI protocol may also be used to
control the orchestra.
Careful control in conjunction with customized instrument definition, allows the
generation of sounds ranging from simple audio effects, such as footsteps or door
closures, to the simulation of natural sounds such as rainfall or music played on
conventional instruments to fully synthetic sounds for complex audio effects or futuristic
music.
For terminals with less functionality, and for applications which do not require such
sophisticated synthesis, a "wavetable bank format" is also standardized. Using
this format, sound samples for use in wavetable synthesis may be downloaded, as well as
simple processing, such as filters, reverbs, and chorus effects. In this case, the
computational complexity of the required decoding process may be exactly determined from
inspection of the bitstream, which is not possible when using SAOL.
I'm looking for typical MPEG-4 Audio applications?
Here are three audio applications for MPEG-4 audio:
- "Playing N-1 Audio Objects"
Transmitting five full multichannel
signals (Audio Objects) which represents five single instruments of an orchestra
(quintet). The listener listens to only four out of five instruments because he likes to
play his instrument instead.
- "Multilingual"
Frequently viewers/listeners to sport programmes are
distracted by the commentator's voice. MPEG-4 will allow a "mix-minus" style of
presentation where everything but the commentator's voice is composited. Alternatively,
one out of a variety of languages, in a multi-lingual service, can be included in the
composition. Note that there is also a multilingual/multiprogramme capability in MPEG-2
AAC, and a multilingual capability in the MPEG-2 BC audio coding standard.
- "Movie Application"
Movie scene at a station. This example contains
four types of audio objects.

Figure 1: Movie scene at a station.
- Conversation object:
The 'welcome' voice in this example is certainly the most important information. The
speech is always located in front of the listener. This conversation may also be available
in multiple languages.
- Background object:
The train will come from a distant location at the center of the scene, pass the listener
and then disappear behind him. In addition the low-frequency effect channel will reproduce
a rumble noise. While the inclusion of this object is desirable, it can be removed in case
of a very low bitrate connection.
- Announcement object:
For the announcement it is sufficient to transmit one low quality speech object. Some
pseudo 3D and some echo effects can easily be generated at the MPEG-4 Player side.
- Background Music:
This orchestra may already be coded with MPEG-2 multichannel and the bitstream will be
used without re-coding.
Multilingual Objects
For an international production more than one conversation object is necessary. The
same scene object can exist in different languages. Each language is a separate audio
object, it will be encoded with an independent audio encoder, and will be selected as
required in the decoder.
Audio Input Formats
All described audio objects are connected to the MPEG-4 encoder system in parallel
(Non-hierarchical structure). Object groups and a more detailed hierarchy structure will
only be handled on the scene descriptor level.

Figure 2: Audio Input Formats.
What is an Audio Object in MPEG-4?
MPEG-4 defines audio objects as "real-world" objects.
A "real-world" audio object can be defined as an audible semantic entity
(voice of one or more speakers, one or more instruments, etc.). It can be recorded with
one microphone in case of a mono recording or with more microphones, at different
positions, in case of a multichannel recording. Audio objects can be grouped or mixed
together, but objects can not easily be split into sub-objects.
One single audio object can consist of more than one audio channel, if we define audio
channels as information, specific for one loudspeaker position. For example, one MPEG-1
audio bitstream will be the coded representation of one object in MPEG-4. This object
contains either 1 channel (mono mode) or 2 channels (dual, stereo or joint stereo mode).
What is "structured audio"?
Structured audio formats use ultra-low bit-rate algorithmic sound models to code and
transmit sound. MPEG-4 standardizes an algorithmic sound language and several related
tools for the structured coding of audio objects. Using these tools, algorithms which
represent the exact specification of a sound scene are created by the content designer,
transmitted over a channel, and executed to produce sound at the terminal. Structured
audio techniques in MPEG-4 allow the transmission of synthetic music and sound effects at
bit-rates from 0.01 to 10 kbps, and the concise description of parametric sound
post-production for mixing multiple streams and adding effects processing to audio scenes.
I�ve heard there is a "Version 2" of MPEG-4 Audio - what�s all this about?
The first version of the MPEG-4 Audio Standard was finalised in 1998
and provides tools for coding of natural and synthetic audio objects
and composition of such objects into an "audio scene". Natural audio
objects (such as speech and music) can be coded at bitrates ranging
from 2 kbit/s to 64 kbit/s and above using Parametric Speech Coding,
CELP-based Speech Coding or transform-based General Audio Coding. The
natural audio coding tools also support bitrate scalability.
Synthetic audio objects can be represented using a Text-To-Speech
Interface or the Structured Audio synthesis tools. These tools are
also used to add effects, like echo, and mix different audio objects
to compose the final "audio scene" that is presented to the listener.
Because of the very tight schedule of the MPEG-4 standardisation,
several promising tools proposed for MPEG-4 were not mature enough to
be included in the first version of the standard. Since many of these
tools provide desirable functionalities not available in MPEG-4
Version 1, it was decided to continue the work on these tools for an
extension of the standard, MPEG-4 Version 2.
With this extension, new tools are added to the MPEG-4
Standard, while none of the existing tools of Version 1 is replaced.
Version 2 is therefore fully backward compatible to Version 1, as
depicted in Figure below.

In the area of Audio, new tools are added in MPEG-4 Version 2
to provide the following new functionalities:
- Error Resilience tools provide improved performance on
error-prone transmission channels.
- Low-Delay Audio Coding tools support the transmission of
general audio signals in applications requiring low coding delay,
such as realtime bi-directional communication.
- Small Step Scalability tools provide scalable coding with
very fine granularity, i.e. embedded coding with very small bitrate
steps, based on the General Audio Coding tools of Version 1.
- Parametric Audio Coding tools combine very low bitrate
coding of general audio signals with the possibility of modifying
the playback speed or pitch during decoding without the need for an
effects processing unit.
- Environmental Spatialisation tools enable composition of
an "audio scene" with more natural sound source and sound
environment modeling than is possible in Version 1.
In the Systems part of MPEG-4, Version 2 specifies a file
format to store MPEG-4 encoded content. Besides other new
tools, also a backchannel for dynamic control and interaction with a
server is specified.
Which additional functionalities are covered by MPEG-4?
While "high coding efficiency" is of course a major functionality of MPEG-4, here are some examples of so-called "additional functionalities": speed control, pitch change, error resilience,
scalability. MPEG-4 addresses several types of scalability:
- Bit rate scalability allows a bitstream to be parsed into a bitstream of lower bit rate
that can still be decoded into a meaningful signal. The bit stream parsing can occur
either during transmission or in the decoder.
- Bandwidth scalability is a particular case of bit rate scalability whereby part of a
bitstream representing a part of the frequency spectrum can be discarded during
transmission or decoding.
- Encoder complexity scalability allows encoders of different complexity to generate valid
and meaningful bitstreams.
- The decoder complexity scalability allows a given bitstream to be decoded by decoders of
different levels of complexity. The audio quality, in general, is related to the
complexity of the encoder and decoder used.
- Error robustness provides the ability for a decoder to avoid or conceal audible
distortion caused by transmission errors.
What is "audio scene description"? How does it work in MPEG-4?
As video scenes are made from visual objects, audio scenes may be usefully described as
the spatiotemporal combination of audio objects. An "audio object" is a single
audio stream coded using one of the MPEG-4 coding tools, like CELP or Structured Audio.
Audio objects are related to each other by mixing, effects processing, switching, and
delaying them, and may be spatialized to a particular 3-D location. The effects processing
is described abstractly in terms of a signal-processing language (the same language used
for Structured Audio), so content providers may design their own empirically, and include
them in the bitstream.
Why should I use an MPEG-4 speech coder instead of an ITU codec?
The ITU-T speech coders currently operate at 6.3/5.3 (G.723), 8 kbps (G.729),16 kbps
(G.728), 32 kbps (G.721) 48/56/64 Kbps (G.722). MPEG-4 speech coders operate at bit rates
between 2 - 24 kbps for the 8 kHz mode and 14-24 kbps for the 16 kHz mode.
Currently ITU-T coders do not operate at bitrates as low 2 kbps for the 8 kHz mode, or
14-24 kbps for the 16 kHz mode. Furthermore, MPEG-4 speech coders provide bitrate
scalability, complexity scalability and multi-bitrate operation from 2 - 24 kbps. The
coding quality of the coder is comparable to that of the ITU coder at corresponding
bitrates. MPEG-4 is standardising a speech coder which can operate down to 2.0kbps. This
will be the lowest bit rate international standard. ITU standards do not support this low
bit rate. The quality at 2.0 kbps is "communication quality" and could be used
for usual conversation, and better than FS1016 4.8kbps coder.
You could utilise the benefits of the MPEG-4 speech coder in various applications. The
MPEG-4-based internet-phone system will offers robustness against packet loss or change in
transmission bitrates. When applied in an audio-visual system, the coding quality is
improved by assigning the audio and the visual bitrates adaptively based on the
audio-visual contents. The MPEG-4 speech coder could be also used in a radio communication
system, where the error robustness is enhanced by changing the bit-allocation between
speech coding and error correction depending on error conditions. These features have not
been realized by any other standards.
Low bit rate is, furthermore, useful for "Party talk". Even though 10 people
are making conversation simultaneously over Internet, one terminal only has to receive
18kbps of bitstream for 9 other people's talk.
Another thing is that usually ITU-T is focusing on real time communication. However,
MPEG-4 low bit rate speech coder is also looking at storage media. The coder has speed
change (without changing pitch nor phoneme) capability and it's very useful for very fast
speech database search/access, where people can identify the content of speech even when
the speed is doubled. The coder also has pitch change capability. These features are not
supported by other speech coding standards.
Finally, as the MPEG-4 speech coders are standardised within the MPEG-4 audiovisual
framework, they interoperate with all of the other MPEG-4 capabilities, such as transport
from distributed servers, synchronisation with synthetic music or visual images, and
parametric effects post-processing. These capabilities are not provided by standards whose
only domain is speech coding.
What is HVXC?
HVXC stands for "Harmonic Vector eXitation Coding", which is a very efficient
speech coding algorithm for low bit-rate speech coding at 1.5 to 4.0 kbit/s. MPEG-4
Version 2 adds a variable Bitrate mode (VBR) mode to HVXC's capabilities.
What are WB-CELP and NB-CELP in MPEG-4 Audio?
The CELP speech coding algorithm in MPEG-4 can operate at 2 sampling rates: 8 kHz and
16 kHz. The former one is often referred to as Narrowband (NB) CELP, the latter one as
Wideband (WB) CELP.
What is TwinVQ?
TwinVQ (Transform domain Weighted INterleave Vector Quantization) ) is a name of audio
coding technique and is one of the object types defined in MPEG-4 Audio Version 1. This
object type is based on a general audio transform coding scheme which is integrated with
the AAC coding frame work, a spectral flattening module, and a weighted interleave vector
quantization module. This scheme has high coding gain for low bitrate and potential
robustness against channel errors and packet loss, since it does not use any variable
length coding and adaptive bit allocation. It supports bitrate scalability, both by means
of layered TwinVQ coding and in combination with the scalable AAC.
Note that some commercialized products such as Metasound (Voxware), SoundVQ (YAMAHA),
and SolidAudio (Hagiwara) are also based on the TwinVQ technology, but the configurations
are different from the MPEG-4 TwinVQ.
What is BSAC?
BSAC stands for bit sliced arithmetic coding that provides one of the forms of
scalability in MPEG-4 audio. In order to make the bitstream scalable, BSAC uses an
alternative to AAC noiseless coding module, although the other coding modules are
identical to AAC. A bitstream encoded by AAC can be transcoded to an BSAC bitstream
noiselessly. BSAC is capable of generating a bitstream with a precise bit rate control in
the range of 16kbps to 64kbps per channel. This bit rate enables the decoder to stop
anywhere between 16kbps and the encoded bit rate with a 1kbps step size. Through use of
this scalablity, the user can experience nearly transparent sound quality at 64kbps and
graceful degradation at lower bit rates. BSAC is best performed in the range of 40kbps to
64kbps, though its operating range is 16kbps and 64kbps.
What is "parametric audio coding"?
Parametric audio coding utilizes a very compact, parametric representation of the audio
signal which is based on the decomposition of the input signal into basic components, such
as sinusoids and noise. In MPEG-4, HVXC and HILN coders are combined to provide very
efficient parametric coding of speech and music at very low bit-rates, respectively. Both
speed and pitch change functionality is provided by MPEG-4 parametric audio coding.
What is HILN?
HILN stands for "Harmonic and Individual Lines plus Noise", which is an
efficient parametric audio coding algorithm for very low bit-rate audio coding at 4.0 to
16.0 kbit/s.
What is "silence compression"?
When silence compression is being applied, silent/almost silent parts of the input
signals are coded more efficiently than active parts. Silence compression can be applied
in MPEG-4 Version 2 CELP coding. The bit rate for these silent parts becomes less than 200
bps when silence compression is being used.
What is a low delay coder?
A low delay audio coder provides data compression while keeping the delay caused by the
encoding / decoding chain low enough to enable two-way communication applications, such as
telephony and videoconferencing (typically around 30 ms for ideal processing). To this
end, MPEG-4 provides both speech coders and the Low-Delay AAC coder. The latter is a
derivative of the standard AAC coder which is defined in MPEG-4 Version 2 to enable high
quality low delay audio coding for general audio signals including speech.
What is error robustness?
Error robustness means that the encoded audio data can be transported over error prone
channels without unacceptable loss in signal quality. MPEG-4 Version 2 realizes this
important functionality with two kinds of techniques. One is called "Error
Resilience". The MPEG-4 Audio Version 2 coding algorithms have the ability to
generate such error resilient bitstreams that can be decoded with minimal degradation even
if they are partially corrupted, if the corrupted part is distinguished. The other
technique is called "Error Protection" (see below).
What is error protection?
MPEG-4 Version 2 contains the Error Protection (EP) Tool which can be used by all
MPEG-4 audio coding algorithms and is able to adapt to a wide range of channel error
conditions. The main features of the EP tool are as follows:
- providing a set of error correcting/detecting codes with wide and small-step
scalability, in performance and in redundancy
- providing a generic and bandwidth-efficient error protection framework which covers both
fixed-length frame bitstreams and variable-length frame bitstreams
- providing an Unequal Error Protection (UEP) configuration control with low overhead
MPEG-4 Audio Version 2 coding algorithms provide a classification of each bitstream
field according to its error sensitivity. Based on this, the bitstream is divided into
several classes, which can be separately protected by the EP tool, such that more error
sensitive parts are protected more strongly. This technique is known as UEP.
Can MPEG-4 be used on error-prone transmission channels?
Yes. MPEG-4 Version 2 specifically addresses this problem by providing means for
"Error Robustness" for each of the MPEG-4 audio coders. See "error
robustness".
What is TTS?
TTS is an abbreviation of the Text-To-Speech conversion system.
Originally, TTS synthesizes speech as its output from input text data.
In other words, the TTS translates the text into a string of phonetic
symbols and the corresponding basic synthetic units are retrieved from a
database. Then the TTS concatenates the synthetic units to synthesize
the output speech with the rule-generated prosody.
What is MPEG-4 TTS interface?
The MPEG-4 TTS interface (TTSI) is designed to pass TTS data to a
speech synthesizer within the MPEG-4 framework. Beyond synthesizig
speech according to the input data with a rule-generated prosody, it
also enables several other functions. They are, 1) speech synthesis with
the original prosody from the original speech, 2) synchronized speech
synthesis with Facial Animation (FA) tools, 3) synchronized dubbing with
moving pictures not by recorded sound but by text and some lip shape
informations, 4) trick mode functions such as stop, resume, forward,
backward without breaking the prosody even in the applications with
Facial Animation (FA)/ Motion Pictures (MP), and 5) users can change the
replaying speed, tone, volume, speaker's sex, and age.
Can MPEG-4 TTSI support various languages in the world?
Yes. We adopted the concept of the ISO 639 language code. In addition to this, we
include the International Phonetic Alphabet (IPA) code to send phoneme symbols.
Why does MPEG-4 TTS interface use IPA (International Phonetic Alphabet) as its standard representation for phoneme symbols?
Because there are a lot of different languages in our world, no single language's
phoneme symbols can cover all possible human speech sounds. The only available method to
represent all various phonemes in this world is to use IPA.
What are the application areas of MPEG-4 TTSI?
Some application areas for MPEG-4 TTSI are as follows:
- Artificial Story Teller (or Story Teller on Demand)
- Synthesized speech output synchronized with Facial Animation (FA)
- Speech synthesizer for avatars in various Virtual Reality (VR) applications
- Voice News Paper
- Dubbing tools for animated pictures
- Voice Internet
- Transportation Timetables
What is standardized for MPEG-4 TTSI?
qFor MPEG-4 TTSI, only the interface bit stream profiles are the objects of
standardization. Because there are already many different types of TTS and each country
has several or a few tens of different TTSs synthesizing its own language, it is
impossible to standardize all the things related to TTS. However it is believed that
almost all TTSs can be modified to accept MPEG-4 TTS interface bit stream profile in an
hour or two by a TTS expert because of the rather simple structure of the MPEG-4 TTS
interface bit stream profiles.
How can MPEG-4 TTS interface operate with FA tools synchronously?
MPEG-4 TTS interface passes phoneme symbols with their duration and average pitch
information to the phoneme-to-FAP (Facial Animation Parameter) converter. Then the
phoneme-to-FAP converter generates FAPs with its duration for the corresponding phoneme
and passes the information to FA tools. From this information FA tools can generate face
images in synchronization with synthesized speech.
How do I encode into an MPEG-4 Structured Audio format?
You can't, today. The techniques required for automatically producing a Structured
Audio bitstream from an arbitrary sound are beyond today's state of the art, although they
are an active research topic. These techniques are often called "automatic source
separation" or "automatic transcription"; there are many references within
the audio processing literature on the capabilities of today's methods. In the mean time,
content authors will use special content creation tools to directly create Structured
Audio bitstreams. This is not a fundamental obstacle to the use of MPEG-4 Structured
Audio, because these tools are very similar to the ones that content authors use already;
all that is required is to make them capable of producing MPEG-4 output bitstreams.
What synthesis method does Structured Audio use for music synthesis?
MPEG-4 does not standardize a synthesis method, but a signal-processing language for
describing synthesis methods. Using this language, any current or future synthesis method
may be described by a content provider and included in the bitstream. This language is
entirely normative and standardized, so that every piece of synthetic music will sound
exactly the same on every compliant MPEG-4 decoder, which is an improvement over the great
variety in MIDI-based synthesis systems.
What is the complexity of a Structured Audio decoder?
There is no fixed complexity which is adequate for decoding every conceivable
Structured Audio bitstream. Simple synthesis methods are very low-complexity, and complex
synthesis methods require more computing power and memory. Since the description of the
synthesis methods is under the control of the content provider, the content provider is
responsible for understanding the complexity needs of his bitstreams. Past versions of
structured audio systems with similar capability have been optimized to provide
multitimbral, highly polyphonic music and post-production effects in real-time on a 150
MHz Pentium computer or simple DSP chip.
One "level" of capability in the Synthetic Object Audio profile of MPEG-4
Audio provides for simpler and/or less normative synthesis methods in RAM- or
computing-limited terminals.
What is SAOL?
SAOL, pronounced "sail", stands for "Structured Audio Orchestra
Language" and is the signal-processing language enabling music-synthesis and effects
post-production in MPEG-4. It falls into the music-synthesis category of "Music
V" languages; that is, its fundamental processing model is based on the interaction
of oscillators running at various rates. However, SAOL has added many new capabilities to
the Music V language model which allow for more powerful and flexible synthesis
description.
There is a WWW page (http://sound.media.mit.edu/~eds/mpeg4)
for composers and sound designers interested in SAOL.
What is the Structured Audio Sample Bank Format (SASBF)?
SASBF is part of the Structured Audio tool in MPEG-4. It provides for powerful
wavetable (or sampling) synthesis capabilities. Wavetable synthesis produces very good
results when synthesizing timbres of natural instruments. The technique uses a relatively
small number of PCM recordings of notes, called "wavetables", as the basis for
synthesizing all the notes required for rendering. In synthesis, the wavetables are pitch
shifted, filtered and enveloped. The particular types of pitch shifting, amplitude
modulation (envelopes) and dynamic filtering used in SASBF allow shifting over a broad
range of pitches.
SASBF provides wavetable synthesis features such as:
- high quality interpolation for pitch shifting
- dynamic filtering
- sound layering
- velocity switching
- reverb and chorus effects
Three main features provide data compression:
- First, only a subset of the required note pitches needs to be represented by wavetables
in the bitstream. The others are generated by processing at runtime.
- Second, the entire duration of a note need not be present in the wavetable. The notes of
many natural instruments are characterized by waveform shapes that vary with time only in
level and amount of high frequency roll-off during the sustain and decay portion of the
note. Wavetables may be truncated after the transient portion of the note is completed.
The waveform from the sustain portion can then be repeated by looping a portion of it. The
high frequency rolloff and amplitude decay are modeled using dynamic filtering and
amplitude enveloping.
- Third, wavetables are stored critically sampled rather than at the system sampling rate.
SASBF can work either as an element ("opcode") in SAOL or in a stand-alone
profile more suitable for ASIC implementation.
Can MPEG-4 give me 3-D Audio spatialization?
Yes. MPEG-4 Version 2 provides 3-D sound positioning, modeling of source directivity,
propagation of sound in the air, and the room acoustic response. Room acoustic modeling
can be done according to two different approaches, namely physical or perceptual. The
former relies on physical (geometrical) description of acoustic characteristics of the
space, such as, reflectivity of walls or reverberation time within a specified region in
the space. In the latter, each sound source is characterized by perceptually relevant
parameters (such as source presence, room envelopment and late reverberance) which are
used to synthesize a room acoustic response for that source.
What does Audio-Composition means?
MPEG-4 contains mechanisms of handling the functionality of the compositor for both
'Basic composition' and 'Advanced effects'. 'Profile 1' handles just synchronisation and
routing. 'Profile Full composition' covers additionally mixing, tone control and sample
rate conversion. 'Profile Advanced effects' includes reverb, spatialisation, flanging,
filtering, compression, limiting, dynamic range control etc.. Profiles 1 and Full can both
be handled within the system part of MPEG-4, i.e. outside the audio decoder. Profile
Advanced effects is handled in the audio/SNHC compositor, the Structured Audio/Effects
(SAFX) box.
Are there new implementations of MPEG-4 Stuctured Audio?
Yes. John Lazzaro and John Wawryznek of the Computer Science division of the University
of California have been working on a translator from MPEG-4 Structured Audio to C, and
it's stable enough now for a developer release. You can download it from
http://www.cs.berkeley.edu/~lazzaro/sa/index.html
Here are a few excerpts from the README:
- Sfront translates MPEG-4 Structured Audio Object 3 bitstreams (plus MIDI functionality
from Object 4) into a C file. The object file produced from this C file consumes input_bus
audio from stdin, and produces output_bus audio on stdout.
- Sfront is free software; you can redistribute it and/or modify it under the terms of the
GNU General Public License (Version 2) as published by the Free Software Foundation.
- Sfront has been compiled using gcc on the following platforms, using the Makefile in
this directory without changes:
- Solaris 2.6 (Enterprise 450)
- HPUX 9.x (715/64)
- Linux 2.2 (4-way Pentium Pro server -- thanks to ISL/Stanford/M. Godfrey)
- IRIX 5.3 (SGI Indigo -- thanks to ICSI/UCB/Nelson Morgan)
- We've been working on sfront since October 1998; the first release was in March 1999. As
of March, sfront was Object 3 compliant, with a few exceptions; in addition, full MIDI
functionality as defined for Object 4 decoders was supported.
- This release of sfront is a developer release. Our own testing of sfront has been
limited to the files shipped in the examples directory. If you are planning to use sfront
to create new programs, expect to find bugs. In addition, our focus until now has been on
getting complete functionality, not code optimization -- a quick look at the C files
sfront produces will confirm this fact.
Under what circumstances can I use MPEG-4 reference software?
First, it should be understood that this software has the goal of describing and
explaining the MPEG-4 standard.
The decoder software accurately implements one method of decoding MPEG-4 bit-streams.
In this sense it is normative. However, there are other ways of correctly decoding MPEG-4
bit-streams. As long as the resulting difference in output from the output signal
generated by this reference software is not larger than the limits set in the conformance
part of the MPEG-4 standard, these other methods are also considered compliant decoders.
For the encoder, the purpose of this software is purely informative. It describes one
example of possible encoding software producing bitstreams which comply to the MPEG-4
standard. This software is not optimized, neither in the speed of execution nor in the
quality of the output signal. For some of the algorithms the picture or sound quality is
similar to what is possible according to state-of-the-art encoding For other algorithms,
(like the AAC t/f-encoding of audio signals) the encoder is just an illustration of
techniques to be used and delivers an output quality far below the one which has been
demonstrated in verification tests of MPEG-4.
The following copyright disclaimer is attached to the software modules in the reference
software:
"This software module was originally developed by <FN1> <LN1>
(<CN1>) and edited by <FN2> <LN2> (<CN2>), <FN3> <LN3>
(<CN3>), … in the course of development of the <MPEG standard>.
This software module is an implementation of a part of one or more <MPEG standard>
tools as specified by the <MPEG standard>. ISO/IEC gives users of the <MPEG
standard> free license to this software module or modifications thereof for use in
hardware or software products claiming conformance to the <MPEG standard>.
Those intending to use this software module in hardware or software products are advised
that its use may infringe existing patents. The original developer of this software module
and his/her company, the subsequent editors and their companies, and ISO/IEC have no
liability for use of this software module or modifications thereof in an implementation.
Copyright is not released for non <MPEG standard> conforming products. CN1
retains full right to use the code for his/her own purpose, assign or donate the code to a
third party and to inhibit third parties from using the code for non <MPEG standard>
conforming products. This copyright notice must be included in all copies or derivative
works. Copyright 199_".
In the text <MPEG standard> should be replaced with the appropriate
standard, e.g. MPEG-2 AAC (ISO/IEC 13818-7), MPEG-4 System (ISO/IEC 14496-1), MPEG-4 Video
(ISO/IEC 14496-2), MPEG-4 Audio (ISO/IEC 14496-3). <FN> should be replaced by First
Name, <LN> by Last Name, and <CN> by Company Name.
I heard about an MPEG-4 player, what is it?
The MPEG-4 player is the name used to describe the reference software that will
interface and demonstrate the tools developed by all the MPEG subgroups. This software
will be updated at each meeting, and will eventually include all the functionalities of
MPEG-4. This software will become available as Part 5 of the standard.
Where can I obtain test pattern and compliance bitstreams for verifying the
performance of an implementation of an MPEG audio tool?
Please see a web site being hosted by AT&T at
http://www.research.att.com/projects/mpegaudio
What does MPEG-4 Audio Version 1 provide above MPEG-2 Audio?
MPEG-4 Audio Version 1 integrates the worlds of synthetic and natural coding of audio. The
synthetic coding part is comprised of tools for the realisation of symbolically defined
music and speech. This includes MIDI and Text-to-Speech systems. Furthermore, tools for
the 3-D localisation of sound are included, allowing the creation of artificial sound
environments using artificial and natural sources. MPEG-4 Audio also standardises natural
audio coding at bit rates ranging from 2 kbit/s up to 64 kbit/s. In order to achieve the
highest audio quality within the full range of bit rates, three types of codecs have been
defined: a parametric codec for the lower bit rates in the range, a Code Excited Linear
Predictive (CELP) codec for the medium bit rates in the range, and Time to Frequency (TF)
codecs, including MPEG-2 AAC and Vector-Quantiser based, for the higher bit rates in the
range. Furthermore, a number of functionalities are provided to facilitate a wide variety
of applications which would range from intelligible speech to high quality multichannel
audio.
What is the difference between MPEG-2 AAC and MPEG-4 AAC?
MPEG-4 AAC has all the tools and functions of MPEG-2 AAC plus the Perceptual Noise
Substitution (PNS) tool, a Long Term Predictor (LTP) as well as extensions to support
scalability. Therefore all MPEG-4 AAC decoders can decode MPEG-2 AAC bitstreams, and
conversely MPEG-2 AAC decoders can decode MPEG-4 AAC bitstreams if none of the MPEG-4
extensions are signalled.
What is MPEG-4 Version 2?
Compared to Version 1, additional tools are added in Version
2. These are: Error robustness which consists of Error Resilience (ER)
and Error Protection (EP), Bit Slice Arithmetic Coding (BSAC) for
fine-grain bitrate scalability, Low Delay AAC (AAC-LD) for coding of
general audio signals with low delay, Harmonic and Individual Lines
plus Noise (HILN) in stand alone mode as well as in combination with
the parametric speech coding scheme HXVC .
- M. Nishiguchi, "MPEG-4 speech coding,"
AES 17th International Conference on High-Quality Audio Coding, Firenze,
Sep. 1999.
- B. Grill, "MPEG-4 General Audio Coder,"
AES 17th International Conference on High-Quality Audio Coding, Firenze,
Sep. 1999.
- H. Purnhagen, "An Overview of MPEG-4 Audio Version 2,"
AES 17th International Conference on High-Quality Audio Coding, Firenze,
Sep. 1999.
- E. D. Scheirer, "Structured audio and effects processing in the MPEG-4 multimedia
standard", ACM Multimedia Systems, in press.
- B. L. Vercoe, W. G. Gardner, E. D. Scheirer, "Structured Audio: Creation,
transmission, and rendering of parametric sound representations", Proc. IEEE, in
press.
See also: MPEG Audio - General Documents, Publications, and Presentations
What is the status of the MPEG-4 Version 1 Standard?
MPEG-4 Audio Version 1 was finalized in October 1998 and published
in 1999.
What is the status of the MPEG-4 Version 2 Standard?
MPEG-4 Audio Version 2 was finalized in December 1999 and will be published
in 2000.



Heiko Purnhagen
10-Mar-2000