Structured Audio: Technical Overview
Up to tools | Back to tools | Forward to musician resources
Introduction
This page gives some technical details, based on signal compression theory, for how and why structured audio works. First, we discuss the format of the MPEG-4 SA bitstream; then we explain why this method provides compression; then we compare structured audio coding to other audio compression methods.
The bibliography has many more details on this sort of theory of structured audio.
SA bitstream format & decoder model
At the beginning a MPEG-4 session involving SA, the server transmits to the client a stream information header, which contains a number of data elements. The most important of these is the orchestra chunk, which contains a tokenized representation of a program written in a special language called SAOL, for Structured Audio Orchestra Language. SAOL is a new language defined in the MPEG-4 standard for the description of digital-signal-processing algorithms. It is particularly optimized for the description of digital-synthesis and digital-effects algorithms, but any algorithm which can be represented as a signal-flow diagram can be coded in SAOL.
The orchestra chunk consists of the description of a number of instruments. Each instrument is a single parametric signal-processing element that maps, in a potentially complex way, from a set of parametric controls to a sound. For example, a SAOL instrument might describe a physical model of a plucked string. This instrument maps from ordered pairs (pitch, amplitude) to a time waveform which, when played, sounds like a string. The model is transmitted through code which implements it, using the repertoire of delay lines, digital filters, fractional-delay interpolators, and so forth that are the basic building blocks of SAOL.
The remainder of the bitstream header contains data that is useful for the SAOL code in some way. For example, if a sampling-synthesis model is transmitted, the bitstream header may contain several sound samples for use in the synthesis process.
The bitstream data itself, which follows the header, is made up mainly of time-stamped parametric events. Each event refers to an instrument described in the orchestra chunk in the header and provides the parameters required for that instrument. Other sorts of data may also be conveyed in the bitstream; these data allow continuous control of instruments during their execution, data needed for continuous processing (for example, frames of vocal-tract-shape data for a singing synthesizer), or tempo and pitch changes in the synthesis process.
It is important to observe that the semantics of parameters are not fixed by the standard, but are defined syntactically, in relation to the model transmitted in SAOL. In contrast to simpler event-based descriptions of synthetic sound such as MIDI, where each event consists of a pitch and an amplitude (the semantics of events are fixed in the MIDI standard), the content creator or encoding system has control and flexibility over the meaning of each parameter in the bitstream.
In further constrast to transmission of synthetic sound with MIDI data, the SA standard allows exact and normative description of sounds. Whereas in the MIDI protocol, the "exact sound" is not specified, in MPEG-4, the content author exactly defines the sound and the algorithms which generate it. Thus, authors are guaranteed that the sound quality will be the same on every compliant rendering device. This is not unusual in the world of audio coding – which depends on such guarantees of decoded quality – but it is rather new in the transmission of audio synthesis.
To decode a bitstream transmitted in the SA format, a real-time synthesis process is executed. First, when the stream information header is transmitted, the orchestra chunk is compiled to low-level instructions, and/or otherwise preprocessed to allow for real-time synthesis. This preprocessing stage may be viewed as reconfiguration of the elements of a digital synthesizer according to the SAOL code transmitted. As with other ISO audio standards, the particular method of implementation is not specified in the standard (only the input-output function is normative), but the standard has been written with efficient compilation to external DSP chips in mind as the most likely manner.
When events arrive in the streaming data, they are dispatched by the decoder to create an instance of an instrument in the orchestra. Many instances of an instrument may be executing simultaneously, and the decoder/scheduler specification in the SA standard contains careful instructions on how they must be kept in synchronization. Each instrument instance creates sound output (typically, one note in a synthetic-music composition); the sounds from all instruments are summed to create the overall orchestra output.
Compression is achieved by eliminating redundancy from audio signals. The more kinds of redundancy which we can discover and exploit in a signal, the more compression we may achieve. Consider a comparison between sounds represented using uncompressed PCM sampling, and sounds represented using various compression techniques.
Entropic coding, or lossless compression, exploits information-theoretic redundancy in the signal. This redundancy originates in the fact that not all sequences of bits are equally likely in the PCM data; some sequences occur more often than others. We design an lossless compression scheme, such as Lempel-Ziv or Huffman coding, to use fewer bits to represent the sequences that occur most often, and more bits to represent the sequences that occur less often. In this way, the average sequence length may be compressed by a factor which depends on the classical information content of the bitstring.
Modern audio coders achieve better performance than lossless compressors by allowing errors, or lossy coding, and exploiting two other kinds of redundancy. First, perceptual coders such as MPEG-AAC have a model of perceptual redundancy. We say that a set of bits in a PCM data sequence is perceptually redundant if changing each bit in the set leads to a result which is not perceptually different, to a human listener, than the original. Once we identify perceptually redundant sets of bits, we don’t need to code them, only to identify them in the transmission process. Modern psychoacoustic coders use sophisticated models of auditory masking to identify sets of bits for which errors in them are masked by other parts of the audio signal.
Second, model-based coders such as the speech coders G.723 and MPEG-4 CELP, exploit what we term process redundancy in audio signals. They make use of a (fixed) process which approximates the physical creation of sound in the human vocal tract – an excitation signal is filtered through an all-pole subtractive filter which shapes the spectrum of the excitation, roughly analogous to the manner in which the vocal tract shapes through spectral subtraction the glottal-pulse excitation sound. In a PCM data sequence containing speech sounds, this model is inherent in each bit of the sound. That is, although there is not an explicit representation of the all-pole-filter model, the presence of this model in the sound consumes bits in the data stream, and the description of this process is redundantly spread all over the sequence.
In this (somewhat unusual) view of speech coding, the coder achieves compression by removing this process redundancy from the signal. The sound is transformed, via linear-predictive coding, into a representation in which it is easier to identify the various parameters of the model. Then, the model is assumed by the coding scheme (it is part of the standards referenced above), and so only the parameters are transmitted. At the receiving side of the transmission, a synthesis algorithm using the same model is used to reconstruct the sound from the transmitted parameters.
SA and other structured-audio compression schemes compress sound by, first, exploiting another type of redundancy in signals we term structural redundancy, and second, by taking a broader and more flexible view of process redundancy.
Structural redundancy is a natural result of the way sound is created in human situations. The same sounds, or sounds which are very similar, occur over and over again. For example, a performance of a work for solo piano consists of many piano notes. Each time the performer strikes the "middle C" key on the piano, very similar sound is created by the piano’s mechanism. To a first approximation, we could view the sound as exactly the same upon each strike; to a closer one, we could view it as the same except for an amplitude-shaping function controlled by the velocity with which the key is struck; for a still-closer one, we could account for the effects of pedals and coupled-oscillation with neighboring strings and nonlinearities in the frame. In a PCM representation of the piano performance, however, each note is treated as a completely independent entity; each time a the "middle C" is struck, the sound of that note is independently represented in the data sequence.
This still holds in a perceptual coding of the sound. The representation has been compressed, since we no longer transmit the perceptually redundant information about very high frequencies or exactly represent the instant directly after a very loud sound. However, the structural redundancy present in re-representing the different "middle C"s as different events has not been removed; the psychoacoustic coder transmits separate and independent data for each such note.
However, with structured coding, we can exploit and remove the structural redundancy from the sound. We assume that each occurance of a particular note is the same, except for a difference which is described by an algorithm with a few parameters. In the model-transmission stage we transmit the basic sound (either a sound sample or another algorithm) and the algorithm which describes the differences. Then, for sound transmission, we need only code the note desired, the time of occurrance, and the parameters controlling the differentiating algorithm. This is a very compact representation, and insofar as we can identify an algorithm which accuractly describes the differences between multiple occurances of the "same" note, an accurate one.
We can go further in this process, of course, by allowing looser bounds on what the "same" note is, and allowing more reconstruction error in the synthesis process. For example, we can observe that the sound of the C# above middle C is very similar to the sound created by modulating the sound of the C up by a factor of 21/12; we can use this fact to create a model of the difference between C and C# and use the same "basic" sound to generate notes at both of these pitches.
Structured audio techniques also allow for a broader view of process redundancy and its exploitation in coding. Consider, for example, the transmission of a sound consisting of speech in a reverberant environment. A narrowband CELP coder has a difficult time achieving high quality with such a sound, because the CELP method is highly optimized for the transmission of clean speech, with little background noise or reverberation. Put another way, the CELP coder assumes a two-stage process model: first, generation of an excitation signal; second, filtering of this excitation signal with an all-pole filter. But our desired sound was created with a three-stage process model: excitation, filtering, and reverberation. The process model assumed in the CELP technique is not appropriate to the different process model which generated the signal.
We can easily transmit this signal accurately in MPEG-4 Structured Audio, though, with no more continuous bandwidth than the CELP coder requires. We transmit, in the header, the CELP-synthesis algorithm and an algorithm for synthetic reverberation. Then, in the bitstream, we transmit parameters for the CELP model. In decoding, the SA processor executes the three-stage process model described above, first synthesizing the excitation function, then filtering it with the vocal-tract model, then reverberating it with the reverberation algorithm. The SA technique can exploit this three-stage redundancy, or indeed process redundancy at any level, because it doesn’t make use of a fixed processing model.
Accurate transmission of sound in such a manner of course depends on our ability to discover or invent the particular reverberation function and the parameters to drive it needed in this situation; similarly, in the piano coding example, we depend on the potential to discover or create the sound models that give the desired results.
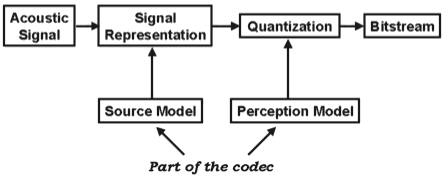
Structured audio coding differs from traditional audio coding in that the sound model is not fixed in the protocol (Fig.1), but dynamically described as part of the transmission stream, where it may vary from signal to signal (Fig. 2). That is, where a traditional audio coder makes use of a fixed model such as a vocal-tract approximation (for LPC coding) or a psychoacoustic making model (for wideband techniques such as MPEG-AAC or Dolby AC-3), a structured audio coder transmits sound in two parts: a description of a model and a set of parameters making use of that model.
Figure 1: In a traditional audio coder, the source model and perception model are defined outside of the transmission (for example, in a standards document). The codec designers do the best job they can at designing these models, but then they are fixed for all content.
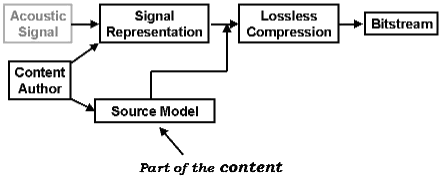
Figure 2: In Structured Audio, the source model is part of the content. It is transmitted in the bitstream and used to give different semantics to the signal representation for each piece of content. There can be a different source model, or multiple source models, for each different piece of content.
The fact that we have great flexibility to encode different sound models in the bitstream means that, in theory, SA coding can subsume all other audio coding techniques. For example, if we wish to transmit speech in CELP-coded format, but only have the SA decoding system available, we can still use CELP: we write the CELP-decoder in SAOL, transmit it in the bitstream header, and then send frames of data optimized for that CELP model as the bitstream data. This bitstream will be nearly the same size as the CELP bitstream; it only requires a fixed constant-size data block to transmit the orchestra containing the decoder, and then the rest of the bitstream is the same size.
SA bibliography (by us and others)